Table of contents
Introduction
In the last part, we've explained how to set up a simple Karton pipeline and start your tasks. If you haven't already, it's probably a good idea to read it now.
Or you can clone the karton-playground repository and follow the rest of this tutorial:
$ git clone https://github.com/CERT-Polska/karton-playground.git
$ cd karton-playground
$ sudo docker-compose up # this may take a while
Your first Karton
In this part, we will focus on the important stuff - how to write your Karton service.
The Karton ecosystem focuses heavily on the reusability of services. One can go a long way using open-source integrations without any custom services. Nevertheless, sooner or later, Karton power-user will be tempted to spin up their favourite editor and contribute to the ecosystem.
One of the primary goals of the Karton framework is to make this endeavour as painless as possible. Simple service should have no more than a dozen lines of code, and the framework will handle all the boilerplate (like logging, monitoring, reliability, security, etc.).
Let's start with a bit artificial example - karton-strings. We'll run a strings utility on every new sample, and send the result as a new file:
class Strings(Karton): # 1. @classes
identity = "karton.strings" # 2. @identity
filters = [{"type": "sample", "stage": "recognized"}] # 3. @filters
def process(self, task: Task) -> None:
sample_resource = task.get_resource("sample") # 4. @resources
self.log.info(f"Hi {sample_resource.name}, let me analyse you!") # 5. logging
with sample_resource.download_temporary_file() as sample_file: # Download to a temporary file
result = subprocess.check_output(["strings", sample_file.name]) # And process it
self.send_task(Task(
{"type": "sample", "stage": "analyzed"}, # 3. @filters
payload={
"parent": sample_resource,
"sample": Resource("result-name", result) # 4. @resources
},
)) # Upload the result as a sample:
if __name__ == "__main__":
Strings().loop() # Here comes the main loop
Save this to a karton-strings.py file, and run in the same virtual env as karton-autoit-ripper from the last part. 1
Let's unwrap this.
1. Classes
class Strings(Karton):
Karton is a base class for every Karton service. Or is it? The (almost) complete source code of the Karton class is:
class Karton(Consumer, Producer):
"""
This glues together Consumer and Producer - which is the most common use case
"""
In fact, Karton is just a combination of Consumer and Producer. You can inherit from them directly. But, most of the time (like in this example), you want to consume and produce tasks simultaneously. So stop worrying and inherit from Karton.
2. Identity and naming
identity = "karton.strings"
What on earth is "identity"? It's a unique identifier assigned to a Karton service. You can run the same script on multiple machines, and the system will load-balance the work automatically. That's possible because of the identity field - all Karton processes with the same identity are exchangeable. For that reason, it must be unique in your pipeline (you can't have two services with the same identity but different code).
All of our Karton identities start with "karton.". That's not required, but we encourage you to do the same. To make things easier, we have a strict naming convention. For example, for Autoit ripper from the last part:
- The identity is
karton.autoit-ripper. - The Python namespace is
karton.autoit_ripper. - The PyPi package is
karton-autoit-ripper. - And the executable provided by that package is called
karton-autoit-ripper. - The Docker image is
certpl/karton-autoit-ripper. - The Github repo is
CERT-Polska/karton-autoit-ripper.
Of course, you don't have to publish your Kartons on PyPi or Docker Hub. But when we do, we follow that naming convention.
3. Filters
filters = [{"type": "sample", "stage": "recognized"}]
Now, this is getting complicated. What are filters?
All Karton consumers have a set of filters they listen to. All Karton tasks have a set of assigned headers.
During a routing phase, Karton-system service 2 will assign tasks to many consumers by matching task headers to consumer filters. For example, filters:
karton.autoit-ripper [
{kind:runnable platform:win32 stage:recognized type:sample}
{kind:runnable platform:win64 stage:recognized type:sample}
]
Mean that the karton.autoit-ripper service is interested in two types of tasks:
- tasks with headers:
kind: runnable,stage: recognized,type: sample, andplatform: win32 - tasks with headers:
kind: runnable,stage: recognized,type: sample, andplatform: win64
These headers are added by karton.classifier, which is usually the first stage of a pipeline - so you don't have to worry about them too much.
In the case of karton.strings, we're interested in all samples of type sample, in the stage recognized. So basically "all executable files".
4. Resources
Resource("result-name", result)
What is that thing? During a Karton development, it turned out that "big files" are important enough to handle them specially. That's why we store all big files in Minio (or other compatible s3 storage) and process them as so-called resources.
There are many helper methods for resources, for example:
sample_resource = task.get_resource("sample")
with sample_resource.download_temporary_file() as sample_file:
result = do_your_processing(sample_file.name)
You can also try:
.content(just return raw bytes for the resource).download_to_file(save to a persistent file).extract_temporary(extract azipfile to a temporary directory).extract_to_directory(extract azipfile to a persistent path).zip_file(download a resource and return aZipFileobject)
5. Logging
Last but not least, logging:
self.log.info(f"Hi {sample_resource.name}, let me analyse you!")
Karton tries to handle all boilerplate, logs included. You can just run your services without any log sink, but you'll see a warning:
/home/msm/.local/lib/python3.8/site-packages/karton/core/logger.py:57:
UserWarning: There is no active log consumer to receive logged messages.
That's because nothing is listening to the Karton logs right now.
The simplest log listener you can spin is a built-in command-line listener - type karton logs in the console:
$ karton logs
[2021-04-24 00:11:09,033][INFO] Logger karton.cli-logger started
INFO:karton.cli-logger:Logger karton.cli-logger started
[INFO] karton.autoit-ripper: Service karton.autoit-ripper started
[INFO] karton.autoit-ripper: Binds changed, old service instances should exit soon.
[INFO] karton.autoit-ripper: Binding on: {'type': 'sample', 'stage': 'recognized', 'kind': 'runnable', 'platform': 'win32'}
[INFO] karton.autoit-ripper: Binding on: {'type': 'sample', 'stage': 'recognized', 'kind': 'runnable', 'platform': 'win64'}
From now on, you'll get logs from all Karton services in your pipeline directly on your stdout.
Of course, standard output is not a great place for logs to go. In production environments, you should use a better logging engine (like karton.splunk-logger).
Now, navigate to http://localhost:8080, log in with admin:admin, upload any executable file, and observe the result:
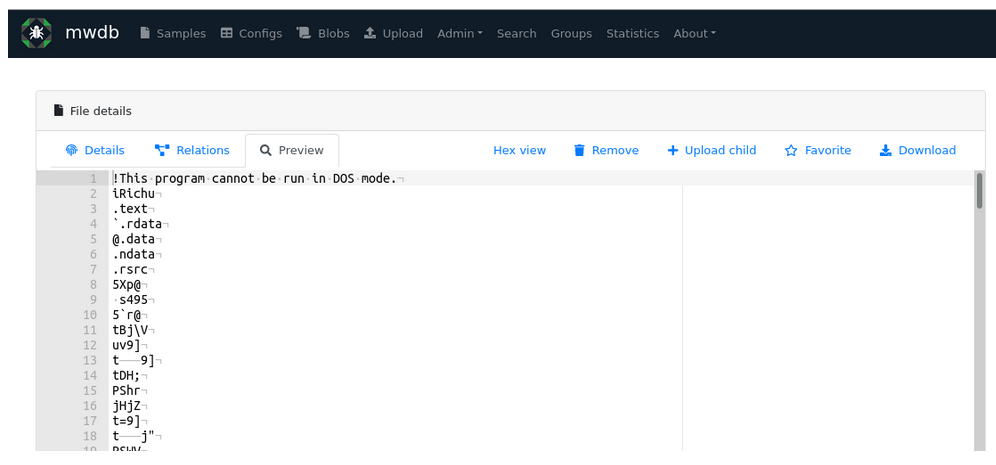
It looks like karton.strings successfully added a child to our sample.
Your first Karton, again
Ok, so what has just happened?
- Our Karton service...
- Called
karton.strings - Received a task of type
sample, and withstagerecognised - Did some pressing, created a new task, and uploaded it back to Karton
- Finally,
karton.mwdb-reporteruploaded the result back to mwdb.
What's next
Of course, running strings on everything is not very insightful. In the next chapter, we'll do something more practical and focus on boxjs - an open-source JScript-malware analysis framework.
And that's still just a beginning. Future topics include:
- Development of your own Karton microservices.
- Other publicly available and ready-to-use services (and where to find them).
- Reliable production deployment.
- Tips&tricks for Karton programmers.
- ...and more
-
If you didn't follow the last part, create a new virtual environment and copy the
karton.inifile from thekarton-playgroundrepo to the working directory. ↩ -
We'll dive deeper into the Karton internals later. For now, let's just say that the
karton-systemservice is a central router that glues everything. ↩
