- niski próg wejścia (zazwyczaj nie wymaga szczegółowej wiedzy z zagadnień inżynierii wstecznej),
- jest generyczne (na przykład podobnego podejścia można użyć dla każdego spambotnetu),
- charakteryzuje się wysoką stabilnością (aktualizacje protokołu sieciowego bota zazwyczaj nie wpływają negatywnie na środowisko analizy).
- trudno się zrównolegla – chcemy śledzić każdą odmianę każdej rodziny malware oddzielnie, a utrzymywanie wielu wirtualnych środowisk jednocześnie wymagałoby sporych nakładów mocy obliczeniowej.
- o ile nie zostaną podjęte dodatkowe środki bezpieczeństwa, złośliwe oprogramowanie w kontrolowanym środowisku ciągle może uczynić komuś szkodę – na przykład będąc proxy dla przestępców, uczestnicząc w atakach typu DDoS albo wysyłając spam.
- nie każda zmiana w botnecie jest widoczna od razu w zachowaniu. Spam oraz adresy C&C łatwo zauważyć w komunikacji, ale nowe próbki złośliwego oprogramowania, webinjecty oraz zmiany konfiguracji są trudne do wyśledzenia behawioralnie.
- jest (relatywnie) lekkie – nawet słaby serwer może śledzić ponad 300 botów bez większych problemów,
- nie jest generowany żaden złośliwy ruch – otrzymane polecenia botmastera z C&C są analizowane (np. nowe próbki są pobierane) i ignorowane,
- zazwyczaj otrzymujemy wszystkie komendy bez opóźnienia, więc bardzo szybko dowiadujemy się o wszystkich zmianach w botnecie.
- szablony e-maili spamowych,
- dodatkowe złośliwe pliki, wyciągnięte ze spamu,
- adresy IP peerów w botnecie.
Opis rozwiązania
CERT Polska jest uczestnikiem projektu SISSDEN (Secure Information Sharing Sensor Delivery event Network). Jednym z naszych celów w projekcie jest stworzenie różnych źródeł informacji związanych z bezpieczeństwem komputerowym, które będą następnie przetwarzane przez odpowiednie jednostki (np. badaczy bezpieczeństwa i akademickich, CERT-y, organy ścigania itp.).
Jednym ze źródeł tych danych (obok honeypotów, sandboxów i podobnych systemów) będzie opracowany przez nas system o nazwie mtracker. Stworzone przez nas rozwiązanie jest rezultatem prowadzonych w CERT Polska szczegółowych analiz złośliwego oprogramowania. Przez ostatnie kilka lat udało nam się przeanalizować wiele różnych rodzin złośliwego oprogramowania i w wielu przypadkach pozyskaliśmy obszerną wiedzę na temat ich sposobu działania i protokołów komunikacji. Wiedza ta pozwala nam symulować działanie rzeczywistych botów i komunikować się z serwerami C&C. Dzięki temu pozyskujemy użyteczne informacje, takie jak próbki albo webinjecty, które można wykorzystać do szeroko pojętych czynności związanych z walką z botnetami
Motywacja
Typowym podejściem do analizy ruchu sieciowego złośliwego oprogramowania jest tzw. sandboxing (uruchamianie go w kontrolowanym, odizolwanym środowisku (sandboksie) i obserwowanie jego zachowania przez duży zbiór filtrów, analizatorów i monitorów).
To podejście ma wiele zalet:
Niestety, nie jest to idealne rozwiązanie. Posiada również sporo wad:
Niektóre z tych problemów mogą zostać częściowo rozwiązane (na przykład sztucznie spowalniając połączenie sieciowe oraz przechwytując wychodzące połączenia SMTP), ale niektóre są integralnie związane z użytym podejściem.
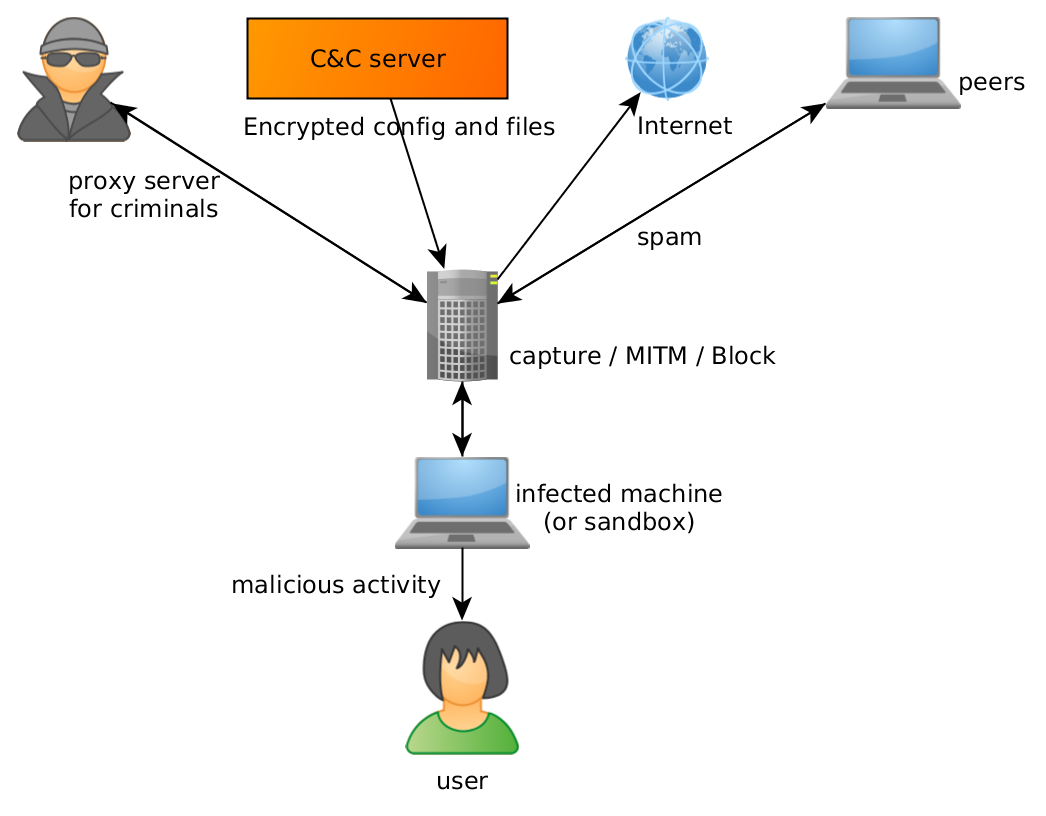
W naszym projekcie rozwiązaliśmy ten problem w inny sposób:
![]()
Ponieważ mamy dużo informacji na temat protokołów komunikacyjnych różnych rodzin złośliwego oprogramowania (dzięki naszym proaktywnym badaniom w tej dziedzinie), zdecydowaliśmy się zaimplementować stos sieciowy kilku rodzin złośliwego oprogramowania i „porozmawiać” z ich serwerami bezpośrednio.
To podejście ma swoje zalety – przede wszystkim natychmiastowo rozwiązuje wspomniane wcześniej problemy:
Olbrzymią wadą tego podejścia jest spora ilość wymaganej pracy reverse-engineerów i programistów. Stworzenie skryptów oraz utrzymywanie ich dla każdej rodziny jest sporym kosztem. Dodatkowym problemem jest stabilność (rutynowe aktualizacje złośliwego oprogramowania mogą spowodować zmianę protokołu sieciowego i zdezaktualizować nasze skrypty).
Architektura
Wszystko zaczęło się jako zbiór luźno powiązanych skryptów, zaprojektowanych, żeby pobierać webinjecty z serwerów trojanów bankowych. Na początku sprawdzała się prosta architektura:
![]()
Kiedy rozpoczynaliśmy, dysponowaliśmy już systemem do wyciągania statycznej konfiguracji złośliwego oprogramowania nazwanym ripper – był to jeden z naszych starszych projektów. Jest on w stanie wyciągnąć różne elementy konfiguracji zapisane na stałe w próbkach malware (na przykład: adresy serwerów C&C, klucze szyfrowania itd.). Zazwyczaj te informacje wystarczają, aby rozpocząć komunikację ze złośliwym oprogramowaniem. W naszym przypadku użyliśmy tych danych, aby półautomatycznie pobierać webinjecty ze znanych nam kampanii.
Rozwiązanie sprawdzało się bardzo dobrze, z czasem jednak zauważyliśmy, że możemy łatwo zaadaptować ten system, żeby pobierał też nowe złośliwe próbki (jako że złośliwe oprogramowanie zazwyczaj otrzymuje aktualizacje przez ten sam kanał co inne komendy). Postanowiliśmy poczynić zmiany w architekturze:
![]()
Wyniki były bardzo dobre, więc rozpoczęliśmy kolejne kroki w tym kierunku. W tym czasie koncentrowaliśmy się również na botnetach P2P i spamie, więc rozpoczęliśmy zbierać coraz więcej informacji:
![]()
W tym momencie zaczęliśmy generować bardzo dużo ruchu i w wielu przypadkach zostaliśmy zauważeni i zablokowani przez operatorów botnetów. Po części dlatego, że wykonywaliśmy bardzo dużo żądań z niewielkiego zbioru adresów IP, ale prawdopodobnie również z powodu naszych okazjonalnych pomyłek (np. używanie tego samego identyfikatora bota albo stałych wartości fingerprintów).
Trafianie na czarną listę to dla nas nic nowego. W tym przypadku, z powodu relatywnie dużej skali operacji, nawet po naprawieniu naszego kodu bycie odblokowanym nie było proste. Z tego powodu, musieliśmy rozpocząć używanie proxy, co znacznie skomplikowało naszą architekturę:
![]()
Od tego momentu wszystkie konfiguracje są śledzone niezależnie z kilku proxy. Ten ruch pozwolił nam również rozwiązać problem geolokalizowanych kampanii – bardzo często zdarza sie, że próbka złośliwego oprogramowania sprawdza swoją lokalizację i odmawia zainfekowania komputerów znajdujących się poza zdefiniowaną strefą (najpopularniejszym przykładem jest Dridex) albo dostarcza inny zbiór injectów/modułów dla każdego kraju (na przykład Emotet). Dodatkowo czasami serwery C&C są trzymane w sieci Tor, więc można się do nich dostać jedynie, korzystając z proxy Tora.
Ostatnią zmianą (jak na razie), którą wprowadziliśmy do naszego systemu jest wzbogacanie funkcji powiązanych z DNS. Jako że używanie domen w TLD ‚.bit’ (dostarczanych przez Namecoin) jest coraz popularniejsze w złośliwym oprogramowaniu, musieliśmy dostarczyć nasz własny resolver (domeny ‚.bit’ nie są oficjalnie dostępne przez główne serwery DNS). Po implementacji tej funkcji zauważyliśmy kolejną szansę – często domeny C&C są zdejmowane szybko po rozpoczęciu kampanii (przez organy ścigania albo zespoły CERT), ale serwer ciągle odpowiada pod swoim oryginalnym adresem IP. Z tego powodu, gdy rozwiązywanie nazwy domeny się nie powiedzie (albo zostanie rozwiązana do sinkholowanej domeny) używany danych z innego naszego systemu – pasywnego DNS:
![]()
Na końcu warto wspomnieć, że ważną częścią projektu jest przeglądarkowy interfejs używany do zarządzania, monitorowania i analizy wyników pracy silnika:
![]()
Wyniki
W pewnym sensie jest to połączenie efektów wielu niezależnych projektów. Dysponujemy kilkoma systemami zbierającymi surowe dane, które są następnie łączone jako dane wejściowe do mtrackera. Pozwala to zebrać przydatne informacje, którymi można się podzielić (jak injecty webowe, szablony spamowe, złośliwe IP itd).
Najważniejsze informacje dostarcza ripper, uzyskując z próbek konfiguracje statyczne, które mogą być użyte do śledzenia serwerów C&C. Przeanalizowaliśmy i możemy wyciągnąć konfiguracje z całkiem sporej liczby rodzin złośliwego oprogramowania. Wykres konfiguracji, które byliśmy w stanie wyciągnąć w podziale na rodziny:
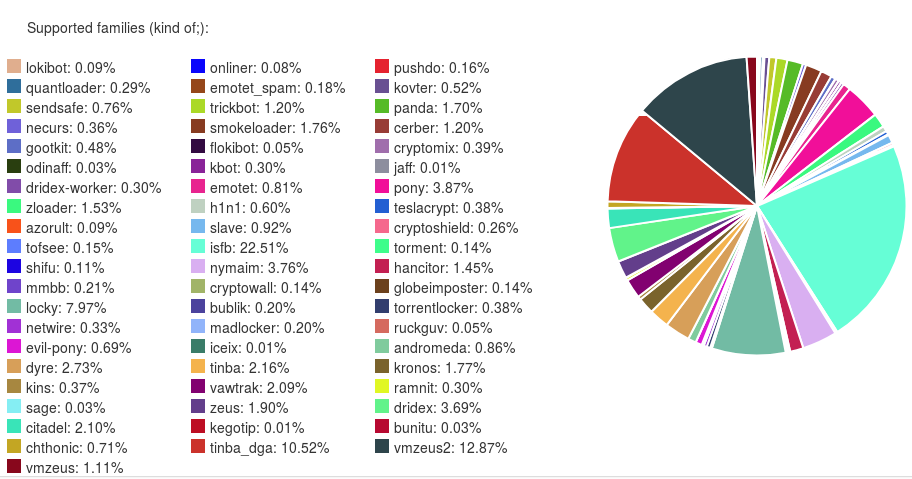
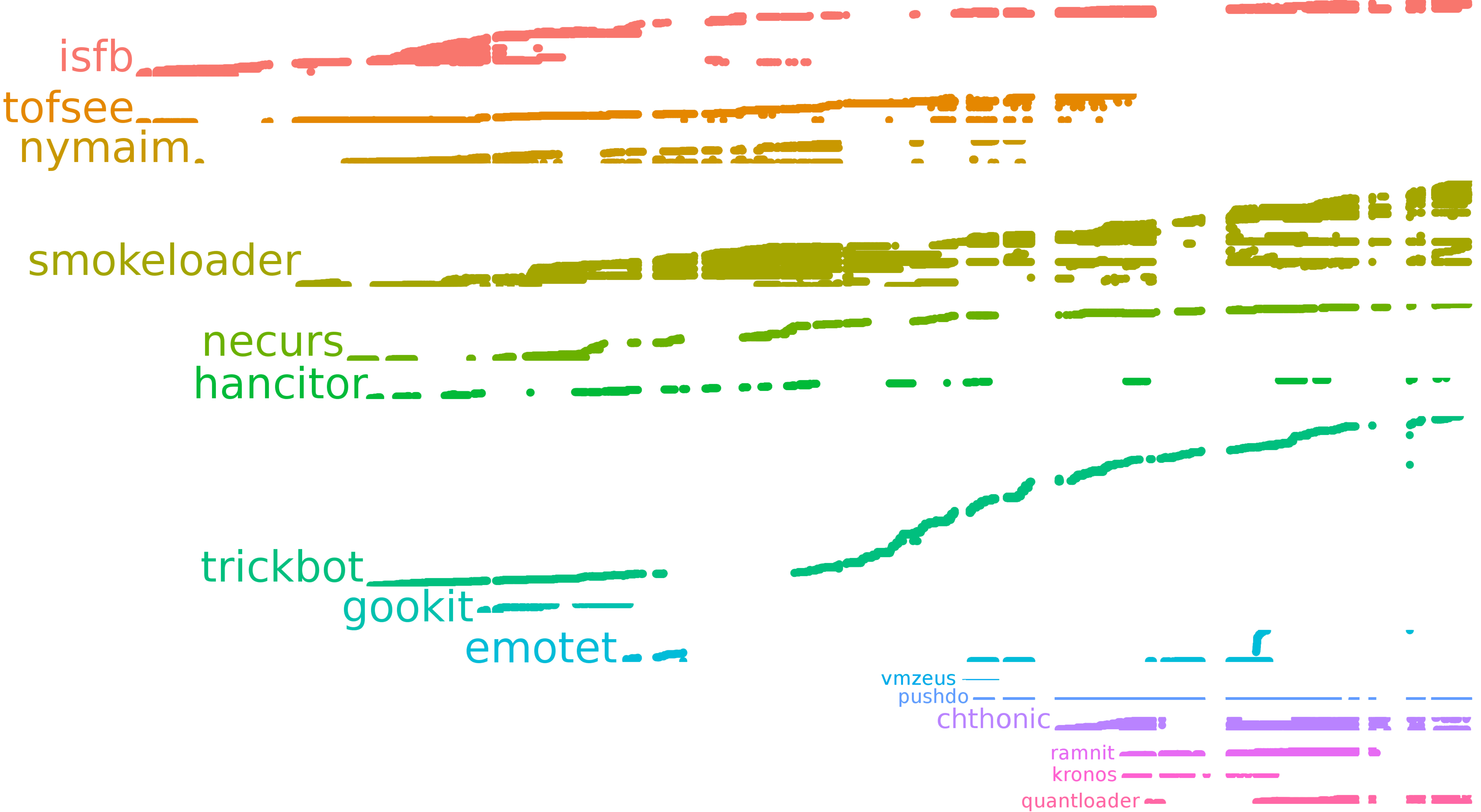
Oczywiście nie wszystkie te rodziny były aktywne bez przerwy. Lepszy pogląd na historię śledzonego złośliwego oprogramowania daje następny obraz (czas „płynie do góry”, konfiguracje są pogrupowane po rodzinach):

W teorii moglibyśmy śledzić wszystkie te rodziny, ale z wielu powodów (jak np. ograniczona ilość środków i czas) skoncentrowaliśmy się jedynie na kilku z nich. Historia konfiguracji, które udało nam się pobrać (pogrupowana po rodzinie):

Albo, w rozszerzonej formie (pobrane konfiguracje podzielone na kampanie, posortowane po rodzinie):