
Zawody CTF (ang. Capture The Flag) bardzo często są znakomitą zabawą, ale pełnią również nieocenioną rolę w doskonaleniu umiejętności specjalistów IT security. Tego typu przedsięwzięcia stawiają wyzwania zarówno przed uczestnikami, jak i organizatorami. Ten artykuł omówi aspekty organizacyjne ćwiczeń z zakresu cyberbezpieczeństwa na przykładzie European Cyber Security Challenge 2018.
- web – aplikacje internetowe w infrastrukturze atakującego, które należy w jakiś sposób zaatakować,
- stegano – zadania w których wykorzystano techniki steganografii (np. analiza pliku wav z ukrytą transmisją tekstową),
- crypto – zadania związane z łamaniem szyfrów, podpisów cyfrowych i innych algorytmów kryptograficznych,
- pwn – zadania wymagające wykorzystania technik binary exploitation (np. buffer overflow, heap exploitation),
- forensic – informatyka śledcza i nie tylko (np. analiza zrzutów komunikacji),
- recon – rekonesans, podążanie za śladami,
- re – zadania związane z inżynierią wsteczną (np. analiza skompilowanych plików wykonywalnych exe),
- misc – wszelkie inne łamigłówki, które nie pasują do powyższych kategorii.
Wprowadzenie
Capture The Flag to najczęściej konkursy odbywające się w określonych ramach czasowych. Do dyspozycji uczestników jest kilka lub kilkanaście zadań o różnych poziomach trudności. Każde zadanie zawiera mniej lub bardziej precyzyjne wskazówki na temat tego, w jaki sposób należy je rozwiązać oraz odnośniki do odpowiednich zasobów.
Typowo występujące kategorie zadań to:
Pomyślne rozwiązanie zadania kończy się uzyskaniem tzw. flagi, czyli dowodu wykonania zadania.
Portal hack.cert.pl
Dwoma kluczowymi potrzebami każdego CTFa jest dystrybucja zadań do uczestników oraz weryfikacja poprawności nadsyłanych przez nich flag. Jeżeli skala przedsięwzięcia jest niewielka, można to zrobić w pełni manualnie posługując się np. pocztą elektroniczną.
Zawody organizowane przez CERT Polska uruchamiamy na specjalnym portalu o nazwie hack.CERT.PL, którego rolą jest zapewnienie rejestracji uczestników, prezentowanie im treści zadań, weryfikacja flag oraz wyświetlanie listy rankingowej w aktywnych konkursach.
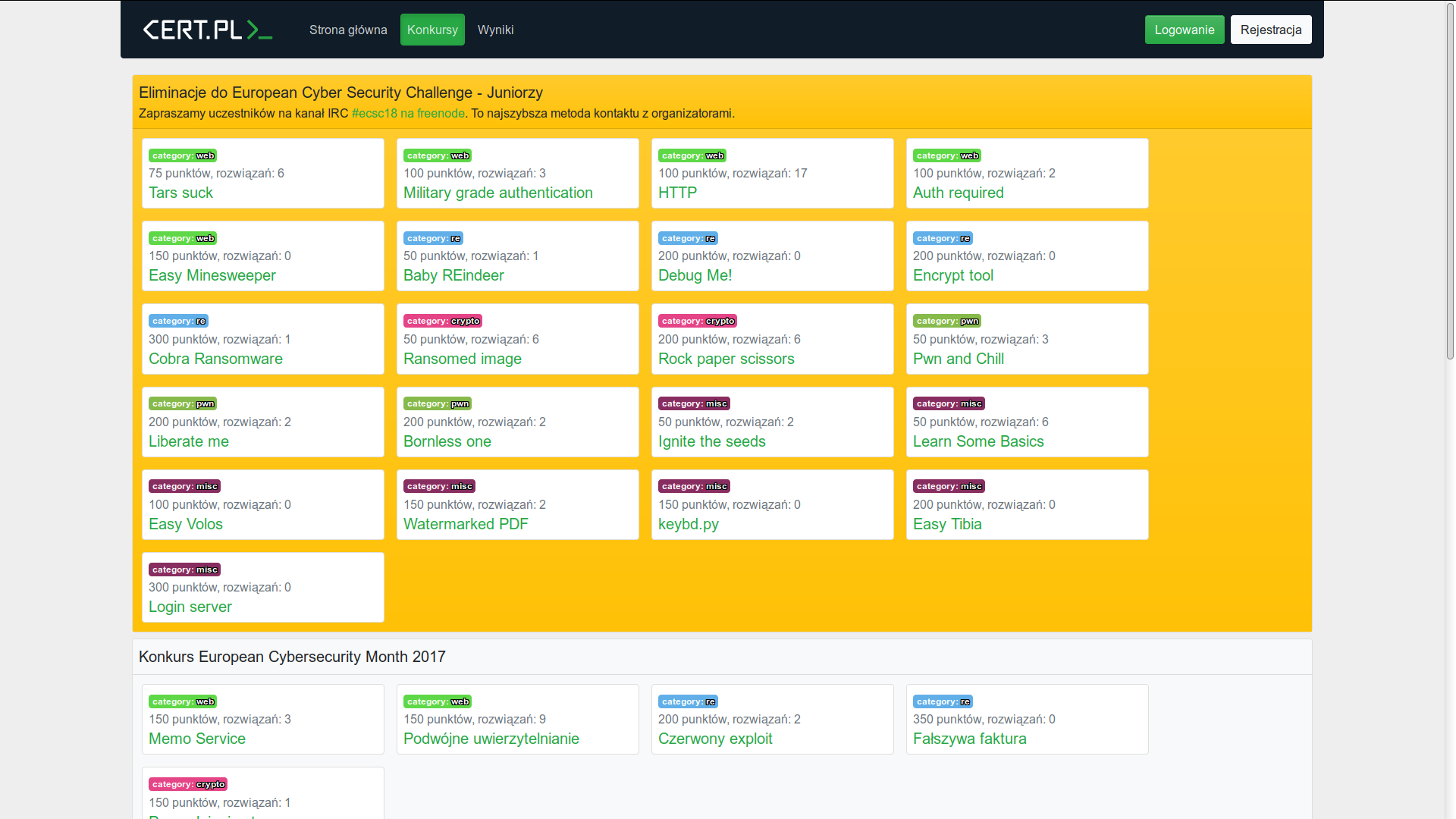
Lista zadań na portalu hack.cert.pl
Usługi hostowane
O ile uruchomienie niektórych zadań z kategorii re, czy crypto jest możliwe bez specjalistycznej infrastruktury, to w kategoriach pwn i web z definicji konieczne jest uruchomienie usługi dostępnej dla uczestników CTF-a.
Jednym z problemów podczas uruchamiania tego typu usług, szczególnie jeżeli konkurs ma wielu autorów, jest różnorodność oczekiwań. Podczas kiedy jeden z autorów potrzebuje stosu Ubuntu + nginx + Node.js do zrealizowania swojego zadania z kategorii “web”, inny może oczekiwać przestarzałej wersji Debiana do uruchomienia wyzwania z kategorii “pwn”. Ponieważ potencjalna różnorodność docelowych środowisk jest bardzo duża, warto rozważyć wykorzystanie Dockera. Należało się również spodziewać, że większość zadań będzie wielokontenerowa (najczęściej w tandemie baza danych + serwer http), wobec czego przydatne okazało się narzędzie Docker Compose.
W ten sposób wprowadziliśmy wymaganie, aby każde zadanie zostało dostarczone w formie paczki z kodem źródłowym zawierającej plik konfiguracyjny docker-compose.yml, który będzie wykorzystywał gotowe obrazy (np. mysql/mysql-server) i własne kontenery zdefiniowane za pomocą plików Dockerfile.
Ponieważ zespół autorów zadań CTF potrafi liczyć nawet kilkanaście osób, taka decyzja projektowa na wstępie wyeliminowała większość problemów “u mnie działa”. Z drugiej strony, dodatkowy czas został poświęcony na udzielenie pomocy kolegom mniej zaznajomionym z tą technologią. Niemniej jednak, część problemów związanych z wdrażaniem zadań została rozwiązana już na etapie ich powstawania.
Plik docker-compose.yml dla zadania webblind
Plik Dockerfile dla zadania webblind
Plik uwsgi.ini dla zadania webblind
Komentarz do listingu: serwis webowy zadania webblind był aplikacją Flask znajdującą się w pliku webblind.py. Instancja Flaska znajdowała się w zmiennej o nazwie app.
Wszystkie usługi były uruchamiane pod czujnym okiem systemd:
Konfiguracja systemd dla zadania webblind (/etc/systemd/system/ctf-webblind.service)
Komentarz do listingu: Po dodaniu nowej usługi należy wywołać komendę systemctl enable ctf-webblind. Następnie można włączyć usługę komendą service ctf-webblind start. Można posłużyć się komendą journalctl -fu ctf-webblind, aby sprawdzić strumień logów tej konkretnej usługi.
Usługi wysokiego ryzyka (nsjail)
W trakcie rozwiązywania niektórych zadań, szczególnie tych z kategorii “pwn”, atakujący może otrzymać możliwość zdalnego wykonywania kodu (RCE) w infrastrukturze zadania.
Tego typu podatność może zostać wykorzystana do zaatakowania infrastruktury ćwiczeniowej, a najbardziej typowym sposobem takiego ataku jest tzw. “fork bomba”, czyli program, który nieustannie uruchamia nowe kopie samego siebie aż do wysycenia zasobów systemu.
Najprostsza fork bomba w języku bash
Komentarz do listingu: uruchomienie fork bomby na własnej, testowej infrastrukturze, jest jednym z ważniejszych testów, jakie należy wykonać podczas jej konfigurowania.
Ponieważ kontenery Dockera nie były projektowane z myślą o uruchamianiu w nich niezaufanego kodu, do dalszego hardeningu infrastruktury wykorzystaliśmy narzędzie NsJail.
NsJail to narzędzie do izolacji procesów przeznaczone dla Linuxa, które wykorzystuje funkcje jądra związane z przestrzeniami nazw, limitami zasobów oraz filtry wywołań systemowych. Dla naszego przypadku szczególnie użyteczny jest tryb “izolacji usług sieciowych w stylu inetd”.
Uruchomienie NsJaila w tym trybie (z przełącznikiem -Ml) spowoduje wystawienie usługi sieciowej na określonym porcie. Dla każdego nowego połączenia NsJail stworzy nową grupę kontrolną, nada jej konkretne ograniczenia oraz uruchomi określony program, podpinając jego strumienie I/O do socketu połączenia.
Ponieważ każda instancja połączenia będzie posiadała swoją instancję grupy kontrolnej i uruchomionego w niej procesu, wysycenie zasobów możliwe jest tylko w kontekście konkretnej grupy. Uruchomienie forkbomby uniemożliwi więc pracę osobie, która to zrobiła, ale nie wpłynie w istotny sposób na pozostałych uczestników.
Przykład pełnej konfiguracji nsjaila:
Plik Dockerfile dla zadania “Pwn and Chill”
Skrypt rozruchowy nsjail.sh
Komentarze do listingów: obraz nsjail budowaliśmy samodzielnie z nieznacznie zmodyfikowanych źródeł. Oryginalny obraz można zbudować w ten sposób:
Warto zapoznać się ze znaczeniem poszczególnych opcji nsjail. Podana powyżej komenda spowoduje zamontowanie w sandboksie katalogów /app, /bin, /lib, /lib32, /lib64 w trybie read-only. Możliwe jest selektywne montowanie urządzeń lub zamontowanie niewielkiego, zapisywalnego tmpfs, unikalnego dla każdej instancji (użytkownicy nie będą interferować ze sobą).
Instalacja lib32z1 jest konieczna, jeżeli usługa do zaatakowania została zbudowana w trybie 32 bitowym (-m32). W przypadku braku tej biblioteki możemy otrzymać mało zrozumiały komunikat /app/pwn_me – no such file or directory.
Usuwanie /var/lib/apt/lists/* w ramach polecenia RUN instalującego paczki pomaga zaoszczędzić do kilkuset megabajtów w wynikowym obrazie Dockera.
Blondies w zadaniach web
Ciekawym przypadkiem są zadania z kategorii “web”, których ścieżka rozwiązywania uwzględnia konieczność wpuszczenia innego użytkownika w atak XSS. Tym użytkownikiem jest najczęściej hipotetyczny administrator w postaci bota znajdującego w infrastrukturze organizatorów.
W zadaniu web-art uczestnicy mieli możliwość skorzystania z formularza kontaktowego, w którym mogli zgłosić niedziałającą podstronę, podając do niej link. Aplikacja internetowa była podatna na atak XSS, a rolą robotycznego administratora było klikanie w spreparowane linki ze zgłoszeń. Boty zrealizowaliśmy za pomocą biblioteki Selenium.
Standardową praktyką podczas tworzenia takich botów jest uruchamianie przeglądarki Chrome w trybie headless, ale ten tryb pracy nie umożliwia ładowania pluginów. Ponieważ w przypadku zadania web-art konieczne było zastosowanie dodatkowej wtyczki, bot do tego zadania był uruchamiany w postaci okienkowej przeglądarki Chrome działającej pod kontrolą xvfb.
Fragment kodu bota do zadania web-art
Jeżeli (tak jak w zadaniu web-art) konieczne jest, aby bot widział docelową aplikację pod adresem 127.0.0.1 można posłużyć się supervisord w celu uruchomienia obu tych rzeczy w ramach jednego kontenera.
Plik Dockerfile dla zadania web-art
Skrypt start.sh
Reverse proxy (nginx)
Ponieważ usługa każdego z zadań wystawia swój własny serwer HTTP, albo przynajmniej FastCGI/uWSGI, udostępnienie ich pod przyjaznymi nazwami hosta wymaga wykonania dodatkowego kroku. W roli bramy użyliśmy serwera nginx, który odbierał cały ruch na portach 80 i 443 i przekierowywał go do odpowiedniego kontenera na podstawie żądanej nazwy hosta. Ponieważ punktem końcowym TLS był frontowy serwer nginx, konfiguracja certyfikatów w serwerach poszczególnych zadań nie była konieczna.
Przykładowa definicja vhosta nginx dla zadania strange-captcha (/etc/nginx/sites-available/strange-captcha)
Load balancing
W zadaniach z kategorii web posiadających wąskie gardła, takie jak np. konieczność interakcji z botem (wspomniany web-art) albo wykonywanie rozszerzonych obliczeń (strange CAPTCHA) konieczne jest oszacowanie liczby równoczesnych użytkowników i rozważenie stosowania load-balancingu.
To zadanie jest znacznie ułatwione dzięki zastosowaniu reverse proxy w postaci serwera nginx. Jako strategię balansowania polecamy ip_hash, ze względu na relatywną prostotę konfiguracji oraz uniwersalność. Uczestnik z danego adresu IP zawsze trafi na tę samą instancję, co zapewni przewidywalne zachowanie aplikacji, nawet jeżeli w wyniku jego działań dojdzie do permanentnych zmian (np. wprowadzenie stored XSS).
Poprawiony docker-compose.yml do zadania web-art
Poprawiona komenda w /etc/systemd/system/ctf-art
Poprawiony config nginx w /etc/nginx/sites-available/web-art
Monitorowanie usług (icinga2)
Ponieważ wynikowa infrastruktura jest dosyć rozległa, ręczne monitorowanie może być nieefektywne ze względu na wynikające z pośpiechu ryzyko przeoczeń i pomyłek. Dodatkowym argumentem przemawiającym za koniecznością automatycznego monitorowania infrastruktury jest jej charakter. Uczestnicy CTF-a atakujący określoną usługę mogą doprowadzić ją do stanu nieprzewidzianego przez autora zadania, a to może przerodzić się np. w nieumyślny atak DoS.
Podczas kwalifikacji do ECSC 2018 naszą infrastrukturę monitorowała Icinga 2 wyposażona w interfejs webowy Icinga Web 2. Klasycznie monitorowaliśmy status vhostów nginxa dla poszczególnych zadań.
Definicja hosta w pliku /etc/icinga2/conf.d/hosts.conf
Swego rodzaju innowacją jest zastosowanie sprawdzeń również wobec innych usług, m. in. serwerów do zadań pwn oraz bardziej skomplikowanych zadań z kategorii web. Autorzy zadań zostali poproszeni o utworzenie prostych skryptów (roboczo zwanych “health checkami”), które udając uczestnika połączą się do danej usługi i wykonają na niej określony exploit wymagany do otrzymania flagi.
Definicja komendy w pliku /etc/icinga2/conf.d/commands.conf
Skrypt check_ctf w katalogu /usr/lib/nagios/plugins
Suplement do wcześniejszej definicji hosta w pliku /etc/icinga2/conf.d/hosts.conf
Komentarze do listingów: ustawianie zmiennych środowiskowych TERM i TERMINFO stanowi obejście problemów z Pythonową biblioteką pwntools, która sprawia trudności z uruchomieniem skryptu w trybie nienadzorowanym.
Wspomniane health checki to pewien rodzaj bardzo uproszczonych testów funkcjonalnych. Ich napisanie nie wiązało się z dużym wysiłkiem, ale pomogły one wykryć szereg nieprawidłowości nawet jeszcze przed uruchomieniem zawodów.
Healthcheck do zadania pwnfck (w katalogu /opt/ecsc18/healthcheck)
Najlepsze efekty w zakresie monitorowania można osiągnąć umieszczając sondy poza wewnętrzną siecią (np. na kupionym do tego celu serwerze VPS w zewnętrznej firmie). Pomoże to odkryć ewentualne problemy z konfiguracją firewalli i innych urządzeń służących do “detekcji intruzów”. Obecności tego typu urządzeń możemy nie być świadomi, a proces rozwiązywania niektórych zadań, ze względu na ich charakter, może wygenerować ruch sieciowy przypominający faktyczny atak na infrastrukturę.
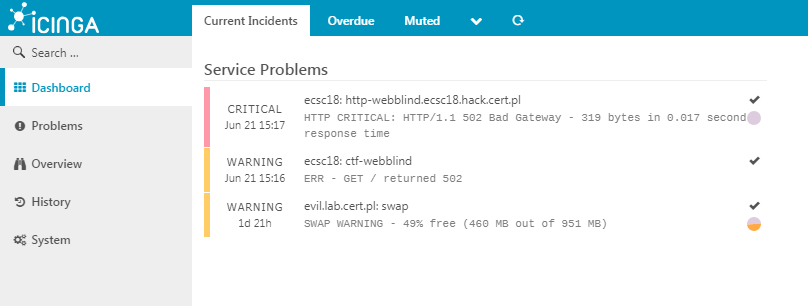 Icinga automatycznie ostrzega nas przed problemami po wdrożeniu wstępnej wersji zadania “webblind”.
Icinga automatycznie ostrzega nas przed problemami po wdrożeniu wstępnej wersji zadania “webblind”.
Ciekawym problemem było monitorowanie botów w zadań z kategorii “web”, do których rozwiązania wymagane było wpuszczenie bota po stronie organizatora w atak XSS (np. wspomniany wcześniej web-art). Jeżeli wektor ataku przewiduje np. wyciek danych poprzez pobranie obrazka z zewnętrznego serwera, skrypt realizujący healthcheck musi uruchomić takowy serwer, aby za jego pomocą odbierać wycieknięte informacje. W tym przypadku posłużyliśmy się pythonowym modułem http.server (wcześniej znanym jako SimpleHTTPServer).
Skrypt realizujący healthcheck do zadania web-art
Komentarz do listingu: ponieważ działanie skryptu powoduje wystawienie usługi na wszystkich interfejsach, należy zablokować zewnętrzny dostęp do portów 11000-11999, np. w ten sposób:
W przypadku tego zadania istnieje pięć różnych instancji kontenera oraz wspomniany wcześniej loadbalancing bazowany na hashu IP. Chcemy jednak wiedzieć, czy nie doszło do zatoru w którejkolwiek z nich, więc skrypt realizujący sprawdzenie przyjmuje numer docelowego portu jako argument wejściowy. Nie możemy również dopuścić do kolizji health checków (jeżeli dwa równoległe skrypty spróbują wystawic usługę na tym samym porcie), dlatego port serwera nasłuchującego jest wyliczany z portu docelowego (np. jeżeli testujemy instancję na portcie 10050 to serwer nasłuchujący pojawi sie na porcie 11050).
Zadanie web-art posiadało zabezpieczenie przed automatycznym zgłaszaniem linków robotycznemu administratorowi w postaci reCAPTCHA, co skutecznie uniemożliwia implementację automatycznych testów. W związku z tym, skrypt realizujący healthcheck do tego zadania był wyposażony w “magiczny token”, który zawsze był uznawany za prawidłowy (serwer pomijał odpytywanie serwerów Google w przypadku wykrycia tokenu).
Powiadomienia
Ponieważ wszystkie awarie wykryte przez skrypty w Icinga 2 muszą zostać skutecznie zgłoszone administratorom, zdecydowaliśmy się na wykorzystanie do tego celu komunikatora Mattermost, z którego już wcześniej wewnętrznie korzystaliśmy.
Hook wysyłający maile z powiadomieniami o awariach został zmieniony w hook postujący wiadomości na odpowiednim kanale komunikatora:

Icinga ostrzega nas przed nadmiernym obciążeniem bota w trakcie trwania CTF-a, co poskutkowało decyzją o przeskalowaniu infrastruktury tego zadania.
Skrypt definiujący komendę /usr/local/sbin/mwall
Dane dostępowe do Mattermosta w pliku /etc/icinga2/mattermost.json
Komentarze do listingów: Pamiętajmy o odpowiednim zabezpieczeniu pliku z hasłem, np. za pomocą komendy: sudo chown nagios:nagios mattermost.json && sudo chmod 640 mattermost.json alternatywą może być również nadanie komendzie mwall flagi setuid oraz ustawienie dostępu do pliku z hasłem wyłącznie dla roota.
Komendy mwall można użyć przekierowując do niej dowolny tekst, np.: echo test | mwall spowoduje wypisanie przez bota wiadomości “test”.
Zawartość skryptu /etc/icinga2/scripts/mail-service-notification.sh
Komentarz do listingu: jeżeli pożądane jest jednocześnie otrzymywanie maili oraz wiadomości na Mattermoście, zamiast zmieniać skrypt mail-service-notification.sh należy dodać nowy szablon powiadomień w pliku templates.conf, zastosować je w pliku notifications.conf oraz zdefiniować nową komendę w pliku commands.conf.
Zmiana sposobu powiadamiania o usterkach przyniosła ze sobą wymierne korzyści. Informacje pojawiały się bezpośrednio tam, gdzie odbywała się cała inna komunikacja związana z organizacją zawodów. To spowodowało, że wiadomości postowane przez robota były dobrze zauważalne oraz dawały możliwość szybkiego przedyskutowania przyczyn awarii z całym zespołem.
Scenariusz awaryjny
Jeżeli z jakiegoś powodu wszystko zawiedzie, albo wystąpią sprzętowe problemy z serwerem, warto mieć możliwość szybkiego uruchomienia zapasowej infrastruktury na innej maszynie. Do automatycznej konfiguracji serwerów posługujemy się narzędziem Ansible, które automatycznie wydaje polecenia przez SSH bazując na deklaratywnej konfiguracji zapewnionej przez administratora.
W definicji inventory określiliśmy jakie zadania mają zostać uruchomione na poszczególnych serwerach, jakie porty mają zostać wyeksponowane na zewnątrz (parametry port_out oraz bind) oraz które usługi mają zostać podpięte pod reverse proxy (wszystkie porty oznaczne jako web_port).
inventory/hosts.yml
W playbooku wydzieliliśmy dwie role – ctf_host dla hostów na których mają zostac uruchomione jakieś zadania oraz reverse_proxy dla hosta, który ma uruchamiać serwer nginx w trybie reverse proxy.
playbook/main.yml
Rola ctf_host uruchamia konkretne zadania poprzez docker-compose i rejestruje je jako usługi w systemd.
playbook/roles/ctf_host/tasks/main.yml
playbook/roles/reverse_proxy/handlers/main.yml
Rola reverse_proxy generuje natomiast konfigurację nginxa dla poszczególnych zadań, o ile zadanie zawiera porty oznaczone flagą web_port.
playbook/roles/reverse_proxy/tasks/main.yml
Podsumowanie
Artykuł przedstawił podstawowe koncepcje oraz problemy związane z organizacją ćwiczeń z zakresu bezpieczeństwa IT w formie zawodów Capture The Flag. Omówiliśmy techniki wdrażania usług za pomocą Dockera, izolację usług podwyższonego ryzyka za pomocą NsJail oraz konfigurację monitoringu usług przy pomocy Icinga 2.
Do powstania tego artykułu przyczyniły się doświadczenia całego zespołu CERT Polska, zdobyte podczas organizacji kwalifikacji do zawodów ECSC 2018 oraz wcześniejszych inicjatyw. Przypominamy, że trwające oraz archiwalne konkursy CTF (współ)organizowane przez CERT Polska dostępne są bezpłatnie na platformie hack.CERT.pl.
