Projekt CCN jest dofinansowany ze środków Europejskiego Funduszu Rozwoju Regionalnego oraz ze środków Budżetu Państwa w ramach Programu Fundusze Europejskie na Rozwój Cyfrowy 2021-2027.

Fuzzing to technika automatycznego testowania oprogramowania polegająca na podawaniu losowych lub celowo zniekształconych danych wejściowych w celu wykrywania błędów i luk bezpieczeństwa. Od lat pozostaje jedną z najskuteczniejszych metod ich znajdowania, ale ma jedną wadę - wymaga wielu godzin przygotowań przed uruchomieniem.
W ramach Centrum Cyberbezpieczeństwa NASK budujemy system, który tę pracę wykonuje samodzielnie: od analizy kodu, przez generowanie testów, aż po klasyfikację znalezisk i gotowe zgłoszenie do twórcy kodu. Pierwsze kampanie pomogły już zidentyfikować realne podatności w szeroko wykorzystywanym oprogramowaniu open source.
Fuzzing pod nadzorem LLM
Proces przygotowania kampanii fuzzingowej przebiega w każdym projekcie według podobnego schematu. Dla każdego nowego testowanego oprogramowania należy:
- przeczytać dokumentację i zrozumieć, jak poprawnie wywoływać funkcje API,
- napisać krótki program testowy, który podaje im losowe dane,
- skonfigurować narzędzia wykrywające błędy pamięci,
- po znalezieniu awarii - przeanalizować raport, sprawdzić, czy to nowa luka czy duplikat, i opisać ją w zgłoszeniu do twórcy.
To powtarzalne, schematyczne zadania, dokładnie te, które duży model językowy (LLM) potrafi dziś wykonać szybciej, a często skuteczniej niż człowiek. Pod jednym warunkiem: trzeba go poprowadzić według jasnej procedury, zamiast pozwolić mu improwizować (ewentualnie halucynować).
fuzzlab to projekt badawczy rozwijany w ramach Laboratorium Fuzzingu i Badania Złośliwego Oprogramowania (FUMAL). Składa się z czterech współpracujących modułów Pythona, biblioteki blisko trzech tysięcy programów testowych dla bibliotek w C, C++, Python i Go oraz bazy danych przechowującej wyniki i metadane wszystkich dotychczasowych kampanii. Cała logika decyzyjna: kiedy ponownie wytrenować model, kiedy wywołać LLM, kiedy zakończyć kampanię; działa lokalnie w Pythonie.
W tej architekturze LLM pełni dwie wyspecjalizowane role. Po pierwsze, działa na konkretnych odcinkach procesu: wstępnie filtruje dane, generuje programy testowe, klasyfikuje znalezione awarie. Po drugie, jest nadzorcą całego pipeline'u - obserwuje, czy poszczególne etapy zachowują się normalnie, wykrywa anomalie (na przykład nagły spadek pokrycia kodu, niestandardowe wzorce w logach, powtarzające się błędy budowania testowanego projektu, niewłaściwa konfiguracja blokująca dostęp do konkretnych ścieżek wykonania), a następnie sam próbuje naprawić problem lub zaproponować ulepszenie procedury. Dzięki temu testy mogą działać nieprzerwanie, bez czekania na interwencję człowieka. To wciąż nie jest agent ogólnego przeznaczenia, który sam decyduje, co robić dalej - to raczej wyspecjalizowany operator działający w jasno wyznaczonych granicach, i właśnie te granice są tym, co czyni go niezawodnym.
Rozwiązanie zostało zaprojektowane jako niezależne od dostawcy modelu AI - sterowanie procesem może przejąć dowolny LLM (lokalny lub chmurowy) albo zewnętrzny agent. Komunikacja odbywa się przez ustandaryzowany interfejs z ustrukturyzowanymi danymi wejścia i wyjścia, więc podmiana modelu lub podłączenie nowego agenta nie wymaga zmian w samym przebiegu procesu.
Pierwsze kampanie pilotażowe potwierdzają, że to podejście działa. Znalezione zostały realne podatności między innymi w ModSecurity (silniku reguł WAF używanym z Apache, nginx i Microsoft IIS) oraz w Oracle VirtualBox. Oba przypadki opisujemy szczegółowo w dalszej części artykułu. Warto zaznaczyć, że fuzzlab jest obecnie na etapie proof-of-concept: projektem badawczym, w którym weryfikowane jest, które elementy tego podejścia sprawdzają się w praktyce. Architektura, dobór sygnałów predykcyjnych oraz sposób integracji z LLM i agentami mogą się jeszcze gruntownie zmienić. Artykuł opisuje stan na dzień publikacji.
Pipeline testów “w pigułce”
Poniżej spojrzenie z lotu ptaka na jedną kampanię — od polecenia operatora do raportu końcowego.
-
Start. Operator wpisuje jedno polecenie w terminalu: podaje nazwę projektu, ścieżkę do kodu źródłowego i opcjonalnie wybiera jeden z gotowych profili konfiguracji.
-
Preflight — lista kontrolna przed startem. Zanim system zaangażuje którykolwiek z fuzzerów, wykonuje weryfikację środowiska uruchomieniowego: czy nazwa projektu jest poprawna, czy katalog ze źródłami istnieje, czy zainstalowane są niezbędne komponenty, czy baza danych ma właściwą strukturę, czy jest miejsce na dysku, i czy poprzedni nieudany przebieg pozostawił jakąś wskazówkę o przyczynie awarii. Każdy błąd krytyczny zatrzymuje kampanię przed startem. Ostrzeżenia są raportowane, ale nie blokują uruchomienia.
-
Przygotowanie do testów. Faza uruchamiana na początku kampanii. Najpierw analizatory statyczne przechodzą przez wszystkie funkcje projektu i wyliczają dla każdej zestaw cech: jak gęsto występują w niej niebezpieczne operacje na pamięci, jak skomplikowana jest jej struktura, z jakimi innymi funkcjami sąsiaduje, jak często była ostatnio zmieniana w historii projektu, co o niej mówią inne narzędzia bezpieczeństwa. Następnie model uczenia maszynowego jest albo wczytywany z dysku (jeśli już istnieje), albo trenowany od nowa na świeżych danych. Dodatkowo istnieje możliwość generowania za pomocą LLM brakujących programów testowych dla funkcji ocenionych jako najbardziej ryzykowne.
-
Cykl roboczy — serce kampanii. Kampania składa się z dziesięciu cykli (wartość domyślna), z których każdy przebiega przez tę samą sekwencję faz opisaną poniżej.
-
Bezpieczniki produktywności kampanii. Po każdym cyklu cztery niezależne warunki decydują, czy jest sens kontynuować kampanię. Sprawdzają: czy znaleziono wystarczająco dużo awarii, czy ranking funkcji się ustabilizował, czy pokrycie kodu już się wysyciło i czy w ostatnich cyklach było wystarczająco dużo „produktywnych" przebiegów. Niespełniony warunek kończy kampanię — a powód zostaje jawnie zapisany w raporcie. To zabezpieczenie przed marnowaniem czasu na coś, co już nie przynosi efektów.
-
Post-mortem. Jeśli kampania zakończyła się słabym wynikiem — bez nowych awarii, z wieloma błędami albo z niewielką liczbą produktywnych cykli — analizator klasyfikuje wynik do jednej z czterech kategorii i zapisuje wskazówkę dla następnego przebiegu. Kolejny etap preflight wczyta tę wskazówkę i ostrzeże operatora zanim system znów wystartuje. To mechanizm uczenia się z własnych potknięć z poprzednich kampanii.
-
Raport końcowy. Po zakończeniu kampanii operator otrzymuje zestawienie zawierające liczbę unikalnych awarii z klasyfikacją CWE i kategorią błędu, decyzje wszystkich warunków wczesnego zatrzymania, różnicę pokrycia kodu względem poprzedniego przebiegu, telemetrię użycia LLM-ów w podziale na poszczególne rodzaje integracji oraz listę zmian w zbiorze testów.
Fazy cyklu roboczego
Każdy z dziesięciu cykli przebiega przez tę samą, stałą sekwencję dziewięciu faz.
-
Fuzzing. Wybrany silnik (LibFuzzer, AFL++, honggfuzz lub centipede) pracuje przez wyznaczony czas, wywołując awarie i generując mapę ścieżek w kodzie, które udało mu się odwiedzić. Algorytm rotacyjnego doboru zasobów — wariant klasycznego problemu wielorękiego bandyty — decyduje, którym harnessom przyznać większy budżet w kolejnym cyklu. Podstawą decyzji są ich dotychczasowe wyniki: programy, które konsekwentnie odkrywają nowe ścieżki w kodzie, dostają więcej czasu; te, które „złapały zadyszkę", dostają go mniej.
-
Pomiar pokrycia. System zapisuje, jak rosło pokrycie kodu w czasie, i szacuje, ile jeszcze nieodwiedzonych ścieżek teoretycznie da się odkryć przy obecnej konfiguracji. To pozwala odpowiedzieć na pytanie: „czy warto kopać dalej w tym miejscu, czy już prawie wszystko, co się dało, zostało znalezione?".
-
Podstawowy triage awarii. Dla każdej nowej awarii system robi cztery rzeczy — najpierw normalizuje ślad błędu do ujednoliconej sygnatury i sprawdza, czy nie widział już identycznej. Potem LLM ocenia, czy to prawdziwy błąd w bibliotece, czy tylko artefakt błędnego programu testowego. Następnie grupuje awarie o tej samej rzeczywistej przyczynie. Na końcu generuje raport do zgłoszenia twórcy oprogramowania.
-
Rotacja programów testowych. Te, które przestały odkrywać nowe ścieżki w kodzie, dostają niższy priorytet w kolejnym cyklu. System może też zmienić konfigurację detektorów błędów, jeśli obecna utknęła w martwym punkcie.
-
Ponowne trenowanie modelu. Model uczenia maszynowego uczy się na świeżych danych. Funkcje, które wywołały awarię, mimo że model wcześniej ocenił je jako bezpieczne, dostają zwiększoną wagę — to wymuszenie na modelu, by w kolejnej iteracji nie popełnił tego samego błędu.
-
Reorganizacja zbioru plików testowych. Duplikaty są usuwane, a trzywarstwowy system hot / warm / cold korpusów eliminuje stare i nieprzydatne próbki.
-
Pogłębione poszukiwania nowych celów. Dla funkcji ocenionych jako najbardziej ryzykowne system uruchamia dodatkowy przebieg z fuzzerem celującym precyzyjnie w konkretne fragmenty kodu. To faza, w której decyzje modelu uczenia maszynowego faktycznie przekładają się na to, gdzie jest alokowany czas procesora.
-
Solver dla danych strukturalnych. LLM generuje wartości, które jednocześnie spełniają reguły gramatyki danego formatu i prowadzą program w pożądane ścieżki. Włącza się dopiero w późnych cyklach, gdy klasyczne losowe mutowanie przestaje przynosić efekty.
-
Raport cyklowy. Pomiary lądują w bazie, strumień zdarzeń płynie do operatora w czasie rzeczywistym, a wszystkie decyzje dotyczące kontynuacji kampanii są zapisywane do późniejszego prześledzenia.
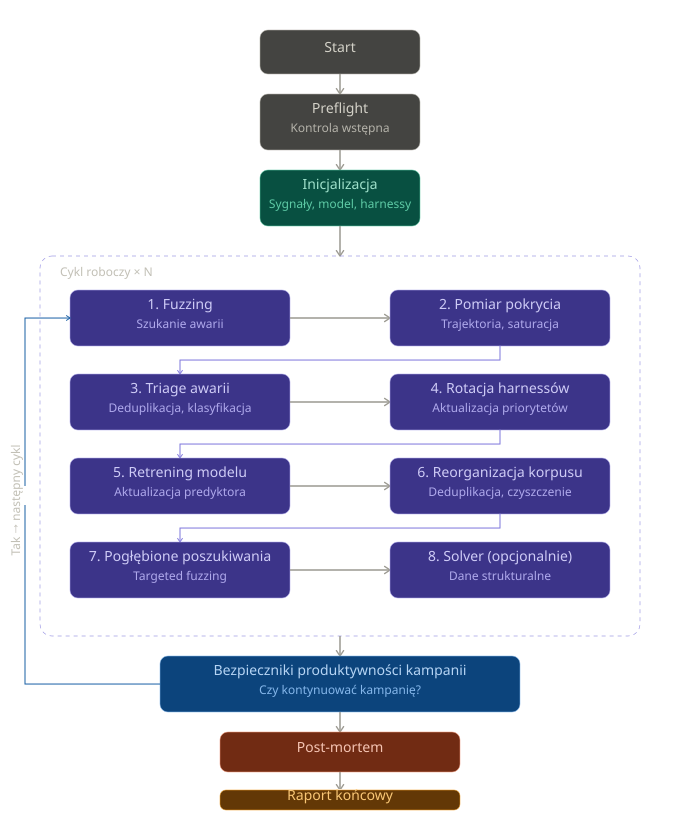
Rys.1 Diagram przebiegu procesu testowego
Architektura wysokopoziomowa
Cztery moduły implementują kolejne etapy procesu - każdy odpowiada za swój wycinek pracy (zarządzanie zbiorem testów, analiza i ranking funkcji, generowanie programów testowych, nadzorca). Działają niezależnie, ale wymieniają się informacjami przez wspólną warstwę danych. Same pliki (powodujące awarię, korpusy testowe), trzymane są osobno na dysku, gdzie każdy plik identyfikowany jest skrótem SHA256 swojej zawartości. W warstwie wymiany zostają tylko metadane wskazujące, gdzie znaleźć oryginał.
Jednostronny przepływ danych
Dane przechodzą przez system sekwencyjnie, moduł po module:
kura (jap. skarbiec) zarządza całym zbiorem plików testowych, który dziś liczy około 35 milionów pozycji. Indeksuje pliki na bieżąco, usuwa duplikaty na podstawie skrótu kryptograficznego zawartości (dwa pliki różniące się choćby pojedynczym bajtem są traktowane jako odrębne, ale identyczne kopie tego samego materiału są scalane do jednego wpisu z licznikiem referencji). Każdy projekt ma własną, oddzielną pulę plików testowych wyselekcjonowanych pod kątem pokrycia kodu, tak by maksymalizować szansę odkrycia nowych ścieżek wykonania przy minimalnej wielkości pliku.
Stary, nieprzydatny korpus testowy jest systematycznie wycofywany trzywarstwowym mechanizmem eliminacji: świeże, aktywne próbki zostają na „gorącej" warstwie szybkiego dostępu; te, które nie odkrywają już nowych ścieżek, schodzą do warstwy „ciepłej"; a po dłuższej nieaktywności trafiają do archiwum, skąd można je w razie potrzeby przywrócić, ale nie obciążają codziennych operacji. Dzięki tej strukturze wzrost zbioru nie obniża wydajności wyszukiwania, a metadane (pochodzenie próbki, projekt źródłowy, historia użycia, wynik ostatniego cyklu) są dostępne praktycznie natychmiast.
kiri (jap. ostrze) to warstwa analityczna pipeline'u i jednocześnie jego najbardziej skomplikowany komponent. Jej zadaniem jest odpowiedź na jedno pytanie: które funkcje w badanym kodzie z największym prawdopodobieństwem zawierają błędy bezpieczeństwa? Aby na nie odpowiedzieć, kiri wydobywa z kodu źródłowego kilkadziesiąt sygnałów hybrydowo - łącząc metody analizy statycznej (badanie kodu bez jego uruchamiania: szukanie znanych wzorców niebezpiecznych konstrukcji, badanie struktury grafu) z dynamicznymi (obserwacja zachowania programu w trakcie wykonania, profile pokrycia kodu).
Do tego dochodzą sygnały kontekstowe: historia systemu kontroli wersji (kto i jak często zmieniał daną funkcję, czy są w niej świeże zmiany), oraz dane z zewnętrznych źródeł takich jak Fuzz Introspector1. Na zebranych sygnałach kiri trenuje równolegle kilka modeli uczenia maszynowego, których głosy łączone są przez meta-model w jeden, spójny ranking funkcji uporządkowany od najbardziej do najmniej prawdopodobnie podatnej na błędy. Ten ranking jest kluczowym sygnałem decyzyjnym dla kolejnego modułu - to on decyduje, gdzie pójdzie budżet obliczeniowy fuzzera w bieżącym cyklu, a co za tym idzie: gdzie pipeline ma realną szansę znaleźć podatność, a gdzie traci czas.
kata (jap. wzorzec) automatyzuje to, co tradycyjnie pisze człowiek po wielu godzinach czytania dokumentacji i kodu źródłowego: generuje gotowe do uruchomienia programy testowe (tzw. harnessy) dla bibliotek napisanych w C, C++, Python i Go. Na podstawie rankingu otrzymanego z kiri moduł identyfikuje funkcje, które warto pokryć fuzzingiem w pierwszej kolejności, a następnie tworzy dla nich harnessy zgodne z konwencjami danego projektu. Każdy projekt może mieć własny zestaw wtyczek opisujących, jak poprawnie wywoływać jego API: jakie argumenty są wymagane, jak inicjalizować struktury wejściowe, w jakim kontekście funkcja działa (np. po wcześniejszym wywołaniu funkcji ustawiającej odpowiednie pola w wymaganych strukturach), jakie wartości brzegowe warto testować. Dzięki temu wygenerowane harnessy nie są generyczne - są dopasowane do tego, jak faktycznie wywołuje się funkcje danej biblioteki, co znacząco zwiększa skuteczność fuzzingu (generyczny harness często „odbija się" od pierwszej asercji wymagającej poprawnie zainicjalizowanego stanu lub generuje false positves). Dodatkowo kata korzysta z LLM jako iteracyjnego “korektora”: po wygenerowaniu wstępnej wersji harnessu kompiluje go, próbuje uruchomić pod fuzzerem, a w razie błędów budowania lub przedwczesnego nasycenia (gdy fuzzer szybko przestaje odkrywać nowe ścieżki) prosi model o poprawioną wersję z konkretną informacją zwrotną. W efekcie fuzzing celuje precyzyjnie we fragmenty kodu wskazane przez model jako ryzykowne, zamiast losowo bombardować całą powierzchnię ataku.
Nigdzie w tym procesie nie ma „pętli zwrotnej" w sensie bezpośredniego zapisu wyników z powrotem do modelu. Informacja zwrotna do uczenia maszynowego wraca dopiero przy następnym cyklu - gdy kiri ponownie wydobywa sygnały z już wzbogaconego zbioru. Dzięki temu nic nie modyfikuje modelu „w locie" w sposób trudny do prześledzenia.
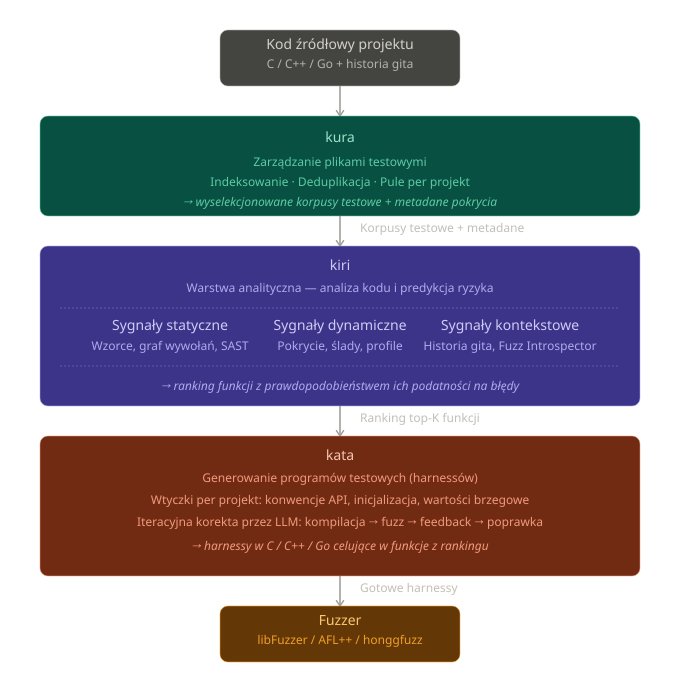
Rys. 2 Diagram przepływu danych pomiędzy modułami kura, kiri, kata.
Uczenie maszynowe
Sercem warstwy uczenia maszynowego jest zespół trzech modeli predykcyjnych - XGBoost, LightGBM i CatBoost - pracujących razem zamiast osobno. To rozwiązanie w rodzaju komisji ekspertów, w której każdy ma trochę inne mocne strony: XGBoost dobrze radzi sobie z sygnałami numerycznymi, LightGBM szybciej skaluje się przy dużej liczbie cech, CatBoost natywnie obsługuje cechy takie jak typ funkcji czy klasa błędu w klasyfikacji CWE.
Predykcje trzech modeli trafiają do meta-modelu drugiego poziomu - prostej regresji logistycznej, która uczy się optymalnie ważyć ich głosy. Stosujemy przy tym dwie techniki warte krótkiego wyjaśnienia:
- Stacking out-of-fold - modele bazowe są trenowane w schemacie 5-krotnej walidacji krzyżowej, dzięki czemu meta-model uczy się na predykcjach modeli, które nie widziały wcześniej tych danych. Bez tej dyscypliny meta-model przeszacowywałby skuteczność modeli bazowych, a ranking funkcji prowadziłby fuzzer w niewłaściwe miejsca.
- Kalibracja Platta - surowe wyniki modeli mają sens porządkowy (wyższy = bardziej podejrzane), ale nie probabilistyczny. Kalibracja zamienia je w prawdziwe prawdopodobieństwa: zamiast „funkcja A jest bardziej podejrzana niż B" można powiedzieć „funkcja A ma 73% prawdopodobieństwa zawierania błędu".
Główną metryką ewaluacji jest Precision@K dla K \= 10, 50, 100 - ile funkcji wskazanych przez ranking jako najbardziej ryzykownych rzeczywiście kryje błąd. AUC2 może być wysokie globalnie, ale to parametr Precision@K decyduje, czy ranking nadaje się do sterowania budżetem fuzzera. Każdy wytrenowany model zapisywany jest razem z hiperparametrami, użytymi cechami i hashem zbioru treningowego - tak, by każdą predykcję dało się odtworzyć podczas badania skuteczności znajdowania błędów.
Skąd biorą się sygnały?
Cechy, na których pracują modele, pochodzą z kilkudziesięciu sygnałów zebranych w trzy poziomy - od najprostszych do bardziej skomplikowanych:
- Poziom 1: szybkie skany - proste przeszukiwanie kodu pod kątem znanych wzorców, funkcja po funkcji.
- Poziom 2: analizy strukturalne - wymagają zbudowania pełnego grafu wywołań programu i porównania wyników kilku narzędzi analizy statycznej.
- Poziom 3: kontekst zewnętrzny - sięgają do historii systemu kontroli wersji (kto i kiedy zmieniał daną funkcję) oraz źródeł zewnętrznych, takich jak Fuzz Introspector.
Każdy z tych sygnałów ma udokumentowane oparcie w literaturze naukowej. Sygnał „prawdopodobieństwa dosięgnięcia funkcji" wywodzi się z pracy Lee & Böhme (FSE 2023, „Statistical Reachability Analysis"), oszacowanie nasycenia pokrycia kodu z metody “jackknife” opisanej przez Liyanage et al. (ICSE 2023, „Reachable Coverage"), a identyfikacja niebezpiecznych operacji na wskaźnikach z pracy Vital (TOSEM 2025, „MCTS-Guided Symbolic Execution Toward Unsafe Pointers").
Telemetria
Każda istotna decyzja “podjęta” przez pipeline zostawia po sobie ślad: w bazie danych albo w strumieniu zdarzeń. Każda faza cyklu tworzy ustrukturyzowane zdarzenie z etykietą z zamkniętej, znanej z góry listy. Operator (lub agent AI) nigdy nie musi zgadywać, co działo się w środku - odpowiedź zawsze jest dostępna w odpowiednim formacie.
Warstwa zerowa: zapis transakcyjny
Na początku utworzony został dedykowany zestaw tabel, w których umieszczane są wyniki właściwej pracy: wartości sygnałów statycznych i dynamicznych dla każdej funkcji, zagregowane wektory cech zasilające model, predykcje wyjściowe, zarejestrowane modele wraz z metadanymi treningu, kolejka zadań z ich statusem i czasem wykonania, metryki dla każdego programu testowego w każdym cyklu, trajektoria pokrycia kodu w czasie, zestawy odwiedzonych ścieżek dla każdego wejścia (w skompresowanej formie), raporty awarii z deduplikacją po skrócie, wyniki skanów przedstartowych z poziomami ważności, oraz raporty stabilności cech. To podstawowa dokumentacja każdej kampanii.
Rys. 3 Weryfikacja parametrów modeli uczenia maszynowego.
Warstwa pierwsza: pamięć podręczna LLM i telemetria integracji
Tę warstwę stanowi telemetria poszczególnych integracji. Każda funkcjonalność wykorzystująca LLM ma własny prefiks klucza i własny licznik w raporcie końcowym. Lista tych funkcjonalności jest długa - obejmuje między innymi: generowanie programów testowych, semantyczny przegląd wygenerowanego kodu, iteracyjne poprawianie, syntezę słowników, triage wyników analizy statycznej, klastrowanie awarii i całego zbioru testów, podpowiedzi na temat luk w pokryciu, wychodzenie ze stagnacji wzrostu pokrycia kodu, dywersyfikację plików testowych, powtórny ranking funkcji, generowanie raportów błędów, ocenę kondycji harnessów, klasyfikację CWE, oraz konsensus walidacyjny i sprawdzanie wykonalności. Łącznie kilkadziesiąt kategorii - każda z własnym licznikiem widocznym w raporcie kampanii i własną wersją pamięci podręcznej.
Warstwa druga: strumień zdarzeń w czasie rzeczywistym
Logi systemu są przechwytywane i przekształcane w zdarzenia: rozpoczęcie cyklu, rozpoczęcie fazy, metryka, błąd, decyzja (w trybie szczegółowego śledzenia), wczesne zatrzymanie, zakończenie kampanii, wynik cyklu (z różnicami produktywności), wskazówka post-mortem, metryki programów testowych. Dane można “zbierać” trzema kanałami: bogato sformatowane do terminala, w formacie JSONL (JSON Lines) do pliku oraz na dashboard webowy w przeglądarce.
Warstwa trzecia: ślad decyzyjny
Po włączeniu odpowiedniej flagi proces zaczyna wyzwalać w każdym cyklu kilkanaście dodatkowych zdarzeń opisujących każdą decyzję: cztery podczas inicjalizacji, pięć dotyczących głównych faz (kiedy włączyć pogłębione poszukiwania, kiedy uruchomić solver dla danych strukturalnych), pięć operacyjnych (jak rozdzielić zasoby pomiędzy różne tryby, jak filtrować pliki testowe, a jak ranking funkcji) oraz trzy warunki wczesnego zatrzymania. Każde zdarzenie ma jednolity format z polami: nazwa bramki, warunek, wynik. Agent czytający strumień widzi nie tylko co się stało, ale również dlaczego.
Warstwa czwarta: telemetria operacyjna
Ostatnia warstwa to telemetria służąca codziennej obsłudze: każde zadanie ma status, fazę i znaczniki czasu; każda awaria ma sygnaturę stosu, klasę CWE i kategorię błędu; każda kampania kończy się raportem z licznikami integracji LLM, listą cykli z metrykami produktywności, zrzutem zmiennych środowiskowych w momencie startu oraz wskazówką post-mortem, jeśli kampania okazała się nieproduktywna.
Samonaprawiający się pipeline
Pipeline został zbudowany z założeniem “na każdym etapie może się coś zepsuć”: LLM może zwrócić odpowiedź, której nie da się sparsować; uruchomienie fuzzera może zakończyć się błędem; trening modelu może zakończyć się gorszym wynikiem niż poprzedni i tak dalej. Poniżej przykładowe mechanizmy wykorzystywane do autodiagnostyki procesu.
Wykrywanie problemów z harnessami
Pipeline na bieżąco monitoruje "stan zdrowia" każdego programu testowego - śledzi tempo wzrostu pokrycia kodu, czas wykonania i moment, w którym harness wpada w stagnację znajdowania nowych ścieżek w kodzie. Na tej podstawie wykrywane są typowe problemy: harnessy crashujące natychmiast po starcie (problem z kompilacją lub inicjalizacją), harnessy działające, ale nieodkrywające żadnych ścieżek (zepsuty wrapper), oraz harnessy wpadające w stagnację przedwcześnie - w pierwszych trzydziestu procentach docelowego czasu wykonania.
W każdym z tych przypadków uruchamiana jest iteracyjna poprawka. LLM otrzymuje kontekst problemu - trajektorię pokrycia, informację zwrotną od detektorów błędów, a w razie potrzeby logi błędów kompilacji. Następnie przepisuje harness od nowa, eliminując ograniczenia blokujące dalszą eksplorację. Wynik trafia do cache’u, a następna inicjalizacja kampanii dostaje już poprawiony program testowy.
Rys. 4 Statystyki jakości harnessów używanych podczas testów.
Walidator awarii chroni pipeline przed false positives
Awarie sklasyfikowane jako nieosiągalne są oznaczane w bazie i pomijane przez wszystkie kolejne kroki korzystające z LLM. Bez tego filtra moduły odpowiedzialne za generowanie raportów błędów, ranking priorytetu i propozycje napraw zajmowałyby się usterkami programów testowych, a nie prawdziwymi błędami.
Raport post-mortem kończy pętlę nieproduktywnych powtórek
Gdy kampania kończy się bez uzyskania oczekiwanych efektów, analizator klasyfikuje jej wynik do jednej z czterech kategorii (wczesna porażka, dominacja błędów, brak wyników, niska wydajność) i zapisuje wskazówkę z konkretnym sugerowanym działaniem. Kolejny preflight tej samej kampanii czyta tę wskazówkę i raportuje ostrzeżenie zanim proces wystartuje - operator widzi komunikat w stylu „kampania X poprzednio zakończyła się brakiem wyników, brakuje konfiguracji bramki" i decyduje, czy zmienić ustawienia, czy świadomie zignorować wskazówkę.
Ochrona modelu przed regresją
W każdym cyklu uruchamiany jest test modelu. Cechy o niestabilnych predykcjach są automatycznie wyłączane przy ponownym trenowaniu. Model przestaje być wykorzystywany nie tylko wtedy, gdy spada jego skuteczność, ale także gdy stabilność predykcji ulega pogorszeniu. Bez tego mechanizmu zespół modeli z czasem zacząłby uczyć się powierzchownych wzorców tekstowych zamiast faktycznych sygnałów strukturalnych.
Interfejs dla agentów AI
fuzzlab od początku projektowany jest pod sterowanie przez agenta AI - każdy punkt wejścia zwraca dane zrozumiałe dla człowieka i przystępne do obsługi w sposób automatyczny. Polecenia CLI zwracają wyniki w ustrukturyzowanym formacie JSON, dostępny jest strumień zdarzeń w czasie rzeczywistym, a wszystkie typowe scenariusze kampanii dostępne są przez nazwane presety, których listę agent może odpytać. Dzięki temu agent może przeprowadzić kampanię od początku do końca, opierając decyzje na ustrukturyzowanych danych, a nie na interpretacji komunikatów tekstowych.
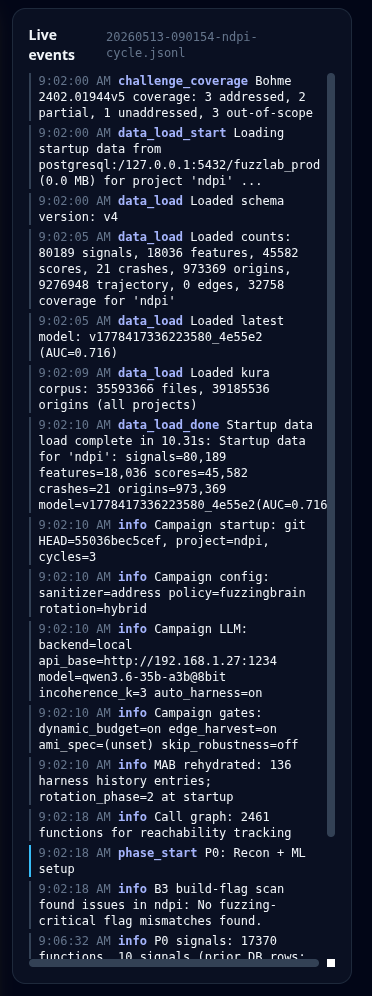
Rys. 5 Przykładowy strumień zdarzeń generowany dla agentów AI w formie graficznej.
Wybrane upublicznione znaleziska
CVE-2026-35251 - Eskalacja uprawnień w VirtualBox Core i możliwość ucieczki z maszyny wirtualnej
Podatność emulacji mechanizmu Intel DMAR - komponentu IOMMU, którego rolą jest izolacja DMA z urządzeń wirtualnych od pamięci hosta. Komponent walidujący wpisy w tabeli kontekstów IOMMU powinien odrzucać te z nieprawidłowymi wartościami pola “translation type” (poza zakresem 0-2 zdefiniowanym w specyfikacji). W wersji 7.2.6 walidacja istnieje na poziomie raportowania (do logu trafia ostrzeżenie o niepoprawnym typie translacji), ale nie blokuje dalszej ścieżki wykonania. Kod kontynuuje przetwarzanie wpisu mimo wykrytego błędu. Jądro systemu gościa może wykorzystać tę lukę, zapisując spreparowany wpis z niedozwoloną wartością typu translacji i adresem pamięci hosta jako bazą tablicy stron, a następnie wykonując DMA z urządzenia wirtualnego - emulator IOMMU, mimo wewnętrznego ostrzeżenia, traktuje request jako prawidłowy, co umożliwia w pomyślnym scenariuszu ucieczkę z maszyny wirtualnej. Łatka pojawiła się w VirtualBox 7.2.8.
CVE-2026-42268 - Integer overflow w operatorach walidacyjnych ModSecurity v3
Podatność w trzech operatorach weryfikujących wrażliwe numery identyfikacyjne: @verifySSN, @verifyCPF i @verifySVNR w projekcie ModSecurity v3 pozwalała zdalnemu napastnikowi zatrzymać proces serwera WWW pojedynczym żądaniem HTTP zawierającym pusty parametr. Wystarczyło proste zapytanie: curl "http://TARGET/path?x=, by reguła WAF zawiesiła cały worker i w konsekwencji zatrzymała obsługiwanie klientów WWW.
Najciekawszym aspektem tej podatności jest jednak nie sam błąd, ale to, że identyczny wzorzec występuje w trzech osobnych plikach: verify_ssn.cc, verify_cpf.cc i verify_svnr.cc - co sugeruje copy-paste z jednego operatora do kolejnych, bez wychwycenia przez proces przeglądu kodu ani przez testy. Sam fakt, że ten błąd przetrwał w bibliotece do 2026 roku, jest argumentem za tym, że nawet dojrzałe projekty bezpieczeństwa zyskują na systematycznym testowaniu w sposób automatyczny.
Statystyki z ostatnich 21 dni (21 kwietnia 2026 -> 12 maj 2026)
- 50 projektów open source testowanych ciągle (38 z co najmniej jedną awarią)
- 16 milionów nowych plików korpusu
- 2057 zakończonych cykli
- ponad 100 tysięcy “surowych” crashy
- 696 unikalnych crashy (550 realnych, 141 false positive)
- 2786 programów testowych w rotacji
- Jakość modeli uczenia maszynowego
- Model dla projektu - 16805 sesji treningowych, średnio 0,981 AUC, pół miliona próbek
- Model globalny - 1191 sesji treningowych, średnio 0,947 AUC, pięć milionów próbek
Zakończenie
“Klasyczny” fuzzing jest tani, istotnie zasobożerne są przygotowania do niego. Fuzzlab powstał jako próba odpowiedzi na pytanie, ile z tych przygotowań można zautomatyzować, traktując AI jako wyspecjalizowane narzędzie pracujące w jasno wyznaczonych granicach, a nie agenta ogólnego przeznaczenia. Opisana architektura to stan na dzień publikacji. Projekt pozostaje w fazie proof-of-concept, a wiele decyzji może się jeszcze zmienić w miarę dalszych eksperymentów.
W tym podejściu fuzzing przestaje być testowaniem samym w sobie, a staje się jednym z elementów szerszego, ciągłego procesu, obok analizy statycznej, predykcji ryzyka, klasyfikacji znalezisk i raportowania. Wartość nie leży w pojedynczej kampanii, ale w pętli, która sama się uczy, sama naprawia i rozwija między iteracjami.
Wyniki obserwowane na obecnym etapie sugerują, że takie podejście - łączące klasyczne techniki fuzzingu z warstwą decyzyjną opartą o uczenie maszynowe i wyspecjalizowane integracje z LLM może istotnie skrócić cykl od identyfikacji nowych podatności bezpieczeństwa do udokumentowanego zgłoszenia luki. Pod warunkiem, że automatyzacja zachowuje zapewnia badaczowi kontrolę, obserwowalność i reprodukowalność wyników.
-
AUC (Area Under the ROC Curve) - popularna miara jakości klasyfikatora, opisująca, jak dobrze model porządkuje przykłady: czy podejrzane funkcje rzeczywiście dostają wyższe oceny niż bezpieczne. Wartość 0,5 oznacza wynik losowy, 1,0 - idealny. AUC opisuje globalną jakość rankingu, ale nie mówi nic o tym, jak dobrze model trafia w sam szczyt - a to właśnie szczyt decyduje o tym, gdzie pójdzie budżet obliczeniowy fuzzera. ↩
